Local Compute and Malleable Software Are a Hedge Against Increasing Cloud Token Pricing
AMD, Intel, Qualcomm, and NVIDIA kept memory separate from the processor. PCIe to discrete GPU memory. Socketed DDR for the CPU. The traditional architecture, which is good for upgradability and bad for AI inference, because every tensor that crosses the bus from CPU memory to GPU memory pays a tax in latency and bandwidth that a unified architecture does not pay.
Five years later, AMD has Strix Halo trying to copy the approach. Qualcomm has Snapdragon X. Intel is reorganizing around something similar. They are four to five years behind, because the decision was hard to walk back once the existing customers expected discrete memory and socketed RAM.
The Fusion Architecture extends the bet. By splitting the chip into two dies but preserving unified memory across the boundary, Apple solved the manufacturing wall without giving up the architectural advantage. M5 Max at 614 GB/s in a 14-inch laptop. M5 Ultra coming in the next Mac Studio. M6 generation built on the same Fusion approach, with more dies and more bandwidth. The roadmap is clear, and the lead is durable.
Source: Memory Is the Machine
There is a reason everyone in China is so hopped up on OpenClaw. They are all in on edge AI. I recently played around with a tiny $10 computer called PicoClaw. It is about a quarter the size of a Square card reader. And it can run a variant of OpenClaw connected to cloud models. It is what they are all excited about in China. The American model is to push the cloud AI, to put it simply. Sell more tokens is the silent mission of Claude, Gemini, and ChatGPT. Elsewhere they want to do things locally.
The chart illustrates the Great Divergence of 2023–2026: while the cost to access “good enough” intelligence (GPT-4 level) has collapsed toward zero, the price for state-of-the-art (frontier) intelligence has stabilized or even risen to fund massive training runs.
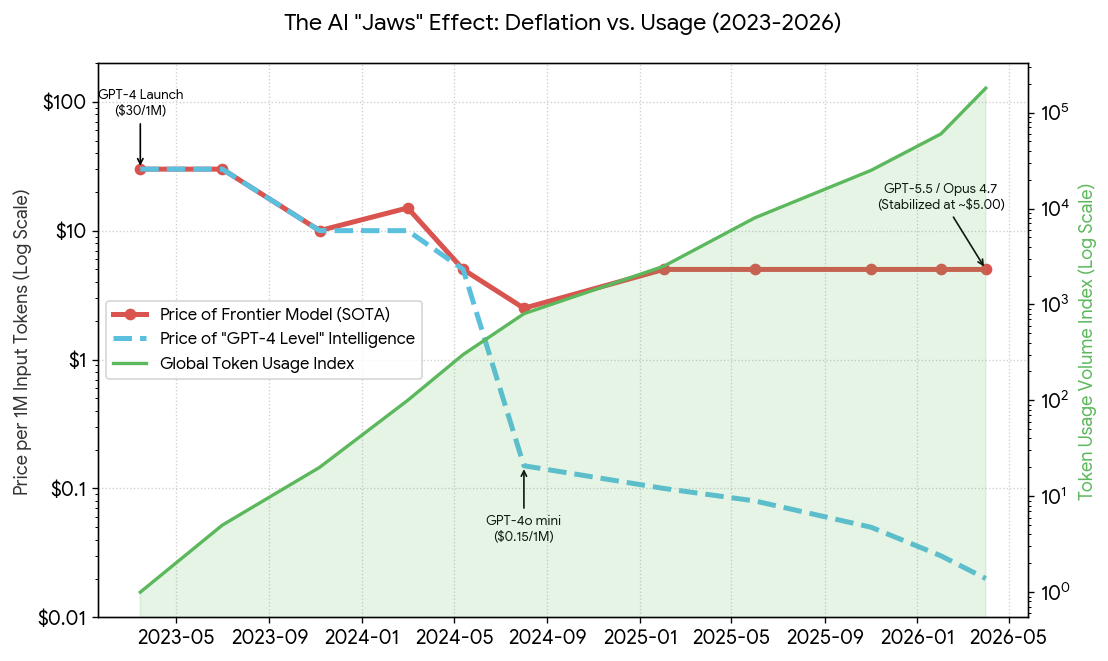
Pricing and token usage isn’t static. The Verge reports: token usage and pricing aren’t currently aligned with frontier lab valuations. As a result, the expectation is that token usage and pricing will increase.
Cloud tokens rule frontier models and enterprise use cases. Usage is exploding, pricing isn’t dropping, and open weight models are finally good enough to run locally. Apple’s hardware sits in the middle — the best bridge between cloud and local, but expensive.
Unified memory is what makes local compute possible. Apple built the architecture for people who couldn’t afford a cloud subscription. The rest of the world is develooping jugaad around these economics.
I’ve spent years in technology and the open web, and that’s why I am hedging against the token economics we’re in. Projects like pi are the critical malleable software that make it possible.
